Même titre que mon plus récent billet car il sera une fois de plus question de belles découvertes (pépites d’or) mais aussi de déceptions intenses. En fait, c’est bien ce qui résume cette édition de la conférence Enterprise 2.0. En effet, nous sommes loin des controverses ou des débats épiques entre McAfee et Thomas Davenport et des keynotes de 2007 soit David Weinberger, Andrew McAfee, Mike Rhodin, Don Tapscott, Ross Mayfield, Thomas Davenport, Derek Burney et Dennis Moore, Stowe Boyd, Jessica Lipnack, etc…

Don Tapscott en 2007 avec en arrière-plan Ross Mayfield
Nous sommes plutôt à l’heure de la mise en valeur des sponsors principaux : Microsoft avec deux keynotes, Jive, Novell, SocialText et SAP et une présence soutenue d’IBM dans les conférences ordinaires et les événements sociaux. Tous les autres sponsors ont eu leur visibilité dans les divers panels mais je me dois de souligner le retenue d’un d’entre eux: BlueKiwi. Chapeau à Carlos Diaz pour ne pas être entré dans le jeu.
Bref, de la seconde journée, je retiens les keynotes du CEO de Jive, Tony Zingale mais surtout celui de Bevin Hernandez, gestionnaire de projet à l’Université Penn State.

Bevin Hernandez – photo Alex Dunne
Même si Zingale a été énergique, incisif et charismatique, c’est à la douce et subtile Hernandez que revient la palme de l’inspiration avec une présentation toute en intelligence sur la psychologie des employés et la gestion des changements. La pyramide de Maslow, bien des gens connaissent mais ses «Magic Quadrants» m’ont beaucoup inspiré ainsi qu’une vidéo qu’elle a présenté et qui montre bien le phénomène d’adoption groupal et de viralité. Voici la vidéo:
Et sa présentation disponible sur SlideShare:
De toute cette seconde journée, ce fut elle mais aussi deux autres présentations qui ont sauvé la mise. Dommage que les deux aient eu lieu en même temps dans des salles différentes. J’ai donc manqué celle proposée pat IBM, intitulée «Evolution of E2.0 at IBM: The frustrations and the Glory» et animée, entre autres, par Rawn Shah, auteur du livre «Social Networking for Business».
Selon les commentaires de @cflanagan, j’aurais raté une bonne démonstration des essais-erreurs-réussites d’une équipe en charge de la mise en action d’une stratégie Web 2.0 en entreprise. Quand on sait qu’IBM fait figure de précurseur en ce domaine, j’imagine en effet que j’ai raté une bonne présentation… Je me suis plutôt présenté à celle des amis Bill Ives et Thierry Hubert afin de constater les progrès de leur bébé Darwin.
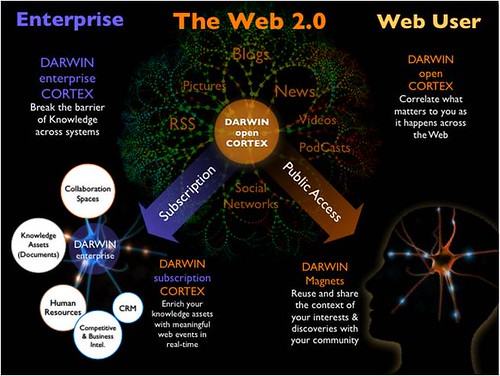
C’est que son évolution m’intéresse au plus haut point car je l’identifie comme l’un des principaux outils nécessaires à la création d’une Mémoire d’entreprise™, le sujet de mon prochain livre. En fait, il s’agit d’un moteur de recherche de conscience (Awareness Engine) ou cortex virtuel, qui se base sur la théorie du Chaos et est en fait, l’un des premiers vrais moteurs du Web sémantique. Et c’est la recherche sémantique et ces outils de conscience virtuelle qui vont permettre aux informations pertinentes et conversations et échanges collaboratifs de remonter à la surface de la mer de données que vont générer les entreprises avec les nouveaux outils d’information, de collaboration et de gestion issus du Web 2.0.
Bref, cette conférence m’a attiré comme un papillon à la lumière du réverbère. Et je je suis pas déçu de l’évolution du produit depuis nos premiers entretiens sur le sujet, il y a deux ans à cette même conférence, Thierry m’ayant été présenté par l’Éminence grise de l’entreprise 2.0 en France, Richard Collin, celui-là même qui avait prédit une conférence 2010 dominée par les commanditaires et les vendeurs de solutions…
En terminant, je ne me permettrai pas de faire de suggestions ou de recommandations à Steve Wylie et son équipe pour la conférence de l’an prochain. Je sais quel travail ils ont abattu et comment il est ingrat mais je tiens à souligner deux tweets issus des commentaires des participants au post-mortem:
- Good lesson learned: Get more interaactive with your audience. More Q&A #e2conf 12:29 PM Jun 17th via TweetDeck
- Great suggestion for #e2conf for next year: Go external ! It works cause we do it at #webcomMT 😉
Deux tweets, deux grandes tendances dans les conférences. La première est de faire des présentations d’au plus 20 minutes et de laisser un autre 20 minutes pour des questions-réponses, favorisant ainsi l’interactivité entre les présentateurs et les participants. La seconde est d’ouvrir la conférence à toute la partie externe du travail des entreprises: Social CRM, eCommerce, eBranding, recrutement 2.0, gestion de crise, géo-promotion, etc. Une très bonne suggestion qui va dans le sens de ce qui se fait déjà webcom, ici à Montréal. Car l’entreprise 2.0, pour une fois, ce n’est pas que l’interne…

