Certains le savent et les autres l’apprendront: je travaille, entre autres, sur la programmation non pas seulement de la conférence webcom-Montréal mais aussi sur un tout nouveau concept de semaine internationale des affaires numériques qui va s’appeler Connect 2012 et va regrouper, en plus de webcom, la Boule de cristal du CRIM ainsi que plusieurs autres événements (ateliers, conférences, diffusions LIVE, galas, soirées, etc.).
Cloud Computing Internet of Things Internet2 LifeLogs Social Business Web sémantique
Bienvenue dans le monde post Web 2.0 !
20 février 2012Je tiens, en ce début de semaine, à republier un billet que j’ai commis en juillet dernier et qui vise dans le mille sur ce qui est en train de se passer dans le merveilleux monde des nouvelles technologies de l’information et des communications (NTIC). Car nous sommes en train de vivre une transition majeure.
Événements Internet of Things Real-Time Web Web 3.0 Web sémantique
Le Web 2.0, so¨passé¨ ?
20 novembre 2010Il en a été un peu question lors du dernier webcom-Montréal et encore plus à Web 2.0 Summit. Il en sera aussi question à LeWeb à Paris dans quelques jours… Je vais aussi en parler dans ma prochaine conférence, mardi prochain devant les membres de la SQPRP. De quoi au juste ? Que le Web 2.0 perd de son actualité au profit de l’Internet des données et applications ainsi que du Web au carré ou plus communément nommé par Tim O’Reilly, Web Squared. Ce faisant et pour des besoins de mémoire, je tiens à republier le billet que j’ai commis sur ce sujet et qui me semble encore tout frais d’actualité:
C’est Tim Berners-Lee qui a mis le feu aux poudres… Depuis le temps que je vous écris que le Web en 2009-2010 fleurira de vos données «It’s all about Data» et que j’écris sur la guerre des données (Data War) qui se joue entre les grands comme Google, Microsoft, Amazon et autres, une guerre qui a pour armes d’accumulation massive le Cloud Computing, le scraping et la portabilité, je croyais donc le sujet entendu. Eh bien, non… Sir Thimoty, qui se présente toujours comme l’inventeur du World Wide Web (www ou encore W3) est venu en rajouter une couche avec une sortie publique fort remarquée, à la conférence TED, en février dernier.
Il est venu parler du futur Web, donc du Web 3.0 où tout n’est que données liées (Linked Data). Il est surtout venu faire la promotion du W3C SWEO Linking Open Data community project. La simple existence de ce projet et ses possibilités a excité les neurones de plusieurs et valu un super billet de vulgarisation dans ReadWriteWeb, édition française. Mais aussi une réplique de Tim O’Reilly et John Batelle, quelques mois plus tard, dans un webcast préparatoire à la conférence Web 2.0 Summit qui aura lieu en novembre à San Francisco. En effet, on ne détrône pas si facilement O’Reilly de sa paternité chiffresque…
Le SlideShare du webcast de Tim O’Reilly le 25 juin dernier
Il est donc revenu à la charge lors de ce webcast en proposant, comme le mentionne l’ami Fred Cavazza dans un excellent billet d’analyse, un Web intermédiaire, soit de Web Squared ou si vous préférez le Web². Comme l’écrit Fred: «Les explications autour de ce Web² sont résumées dans l’article fondateur suivant : Web Squared: Web 2.0 Five Years On ». C’est un article sur le site de Web 2.0 Summit qui appuie leurs prétentions mais les deux compères ont aussi pris le soin de rédiger un «White Paper» pour officialiser leur paternité sur le thème et l’idée.
Ce qui n’a pas empêché une autre grosse pointure, soit Dion Hinchcliffe de venir rajouter son propre grain de sel avec le billet: The Evolving Web In 2009: Web Squared Emerges To Refine Web 2.0. Hinchcliffe, qui écrit aussi pour ZDNet, donne des ateliers sur l’entreprise 2.0 à la conférence bostonienne Enterprise 2.0 et est, pour le bonheur de ceux et celles qui assistent à ses «workshops», un fervent adepte des schémas. Il a donc pondu le schéma suivant:

Hinchcliffe présente donc le Web² comme une suite logique et naturelle du Web 2.0, une forme d’évolution ou comme le dit Fred de «maturation qui va nous amener vers la prochaine itération majeure», soit le Web 3.0, le Web sémantique où les données et les liens fusionnent, là où se crée finalement une interrelation entre toutes les données afin de finalement donner un sens au Data Cloud, un sens généré au départ par les usagers eux-mêmes comme dans le projet original de Linked Data de Berners-Lee.

Sa croissance est exponentielle. Ce nuage va devenir immense et pas seulement avec les données personnelles et tout ce que cela implique au niveau de leur entreposage et de leur portabilité mais aussi de leur protection et sécurité mais aussi celles des entreprises, à l’externe aussi bien qu’à l’interne… Un immense Cloud planétaire! Certains se réfèrent déjà au concept de Neural Net développé en science fiction et en référence aux travaux sur les Artificial Neural Networks, associés à l’intelligence artificielle. D’autres, comme Thierry Hubert, avec son projet Darwin, parlent de Virtual Cortex, issu directement de la «Théorie du Chaos»…

Bref un SupraNet où des agents intelligents se chargent de faire les corrélations pour récupérer de cet immense et chaotique nuage de données et de liens, les informations pertinentes, requises par les utilisateurs.
Et dire que Gene Roddenberry, il y a bien des années, a décidé de donner un nom très particulier au premier robot à cerveau positronique doté d’intelligence artificielle à apparaître dans sa série Star Trek. Ce nom, vous l’avez deviné, c’est : Data…
Cloud Computing Communication interactive Entrepôts de données Entreprise 2.0 Études Internet Ideagoras Mémoire d'entreprise Real-Time Web Web sémantique
Le Web en 2010: le vertige des listes et trois tendances lourdes!
30 décembre 2009Je dois vous avouer que j’ai régulièrement le vertige, surtout en hauteur mais aussi à l’approche du Nouvel An… En cette période de l’année, je ressens un sentiment bizarre qui a été identifié hier par l’amie Suzanne Lortie. Elle en a même fait le sujet de son dernier billet sur son blogue: Le vertige des listes…
Un vertige face à un véritable fléau qui afflige régulièrement les médias aussi bien traditionnels que Web mais aussi les blogues, les statuts Facebook et Twitter, surtout en cette période de fin d’année où les bilans sont chose courante. D’ici au début de 2010, on ne verra que ça : top ten IPO candidates for 2010 chez TechCrunch, 10 ways social media will change 2009 ou encore Top 10 YouTube Videos of All Time chez ReadWriteWeb et ainsi de suite.
Je dois avouer qu’il serait aisé de tomber dans cette facilité et de faire mon propre décompte de mes dix meilleurs billets de 2009 ou encore de faire mon appréciation des dix moments marquants du Web 2.0 en 2009 ou encore mieux faire de la prospective et de parler des 10 technologies qui marqueront la prochaine décennie!
Facile et payant. En effet, ces classements, listes et décomptes vous valent habituellement une excellente couverture sur Twitter comme le démontrent les 2 626 tweets faits à date sur ces prédictions de RWW. Et que dire du trafic encore plus important généré sur l’article certes, mais aussi sur l’ensemble du blogue par le biais des liens fournis sur les articles similaires.
Bref, vous le comprendrez, je n’aime pas cette sensation de vertige des listes, de catégorisation, de tout vouloir mettre dans des cases, même si les listes peuvent parfois être utiles comme elles l’ont été au tout début de leur apparition sur Twitter.
Tendances 2010
Mais j’aime bien, à chaque fin d’année, faire un tour de tous les blogues que je suis régulièrement (eh oui, «listés» dans mon Netvibes) question de faire un peu de veille sur ce que seront les grands courants ou tendances lourdes qui vont influencer le Web au cours de la prochaine année mais aussi au cours des suivantes car les grands courants de fond sont souvent mouvants, changent de forme ou de direction.
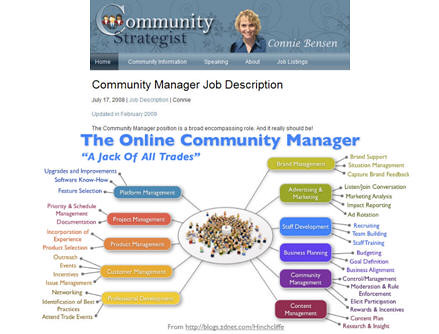
Ainsi, plusieurs blogues maintiennent que 2010 sera l’année des gestionnaires de communauté. Certes, plus il y aura de communautés 2.0 sur le Web mais aussi dans l’entreprise, plus il y aura besoin de personnes pour les gérer et les animer. Donc, oui, on en verra de plus en plus, regroupés dans des listes ou communautés comme celle de Luc Legay.
1) L’Internet des données
Mais ce ne sera pas le grand courant de fond. Pour le trouver, il ne faut pas aller très loin. J’en parle régulièrement sur ce blogue : Les données. Et en cela, ReadWriteWeb confirme dans son analyse de la première de cinq grandes tendances pour 2010.
ReadWriteWeb’s Top 5 Web Trends of 2009:
1. Structured Data
2. The Real-Time Web
3. Personalization
4. Mobile Web & Augmented Reality
5. Internet of Things
Eh oui, encore une liste… Les «Structured data» ou encore «linked data», le crédo de Tim Berners-Lee, seront à l’avant-scène tout comme le Web Squared ou Web². En effet, avant de parler de Web 3.0, de Web sémantique ou de Web 3D, certains dont Tim O’Reilly, ont vu 2010 et les prochaines années comme des années de transition et ont théorisé sur cette dernière. Pour en savoir plus, je vous reporte à CE BILLET que j’ai commis plus tôt cette année.
Mais il est tout aussi important pour l’évolution du Web d’être capables de mettre en place une infrastructure matérielle et logicielle robuste et sécuritaire. Où iront toutes les données que nous générons, individus comme entreprises? Ces données gérées et entreposées sont-elles sûres, protégées ? Le Cloud Computing est-il à l’abri des «hackers»? Qu’arrriverait-il aux données en cas de sinistre, de faillite ou de vente de l’hébergeur? Le «nuage» sera-t-il à l’origine d’une cyber-guerre?

Voilà une foule de questions qui seront à l’avant-scène et je vous conseille de lire l’excellente analyse faite par la MIT Technology Review et intitulée «Security in the Ether». Vous y trouverez plusieurs réponses. C’est et de loin, le meilleur article sur le sujet depuis des lunes…
2) Real-Time Web et Web mobile
Et je souscris à l’analyse faite par RWW sur le Real-Time Web et le Web mobile et ce n’est pas pour rien que nous étions plus de 2 300 réunis à LeWeb09 en décembre pour entendre les ténors du Web, dont Evan Williams, nous parler de Skype, Twitter ou UStream mais aussi de Square, de géolocalisation et de la popularité croissante de Foursquare ou Gowalla. Ce qui devrait logiquement déboucher sur l’Internet of Things mais la réalité augmentée elle, devra attendre, n’en déplaise à certain(e)s…
3) L’expertise des retraités
Et n’en déplaise à d’autres, 2010 sera aussi l’année où l’on verra coexister en entreprise quatre générations différentes d’employés et en 2015 l’arrivée d’une cinquième et cela est aussi une tendance lourde… Eh oui, fallait bien que je traite aussi de l’entreprise 2.0. Donc, finie l’utopie de la retraite à 55 ans! Fini aussi l’illusion que les générations Y et NetGen allaient balayer les BabyBoomers et leurs prédécesseurs.
Le Harvard Business Review a ainsi relevé les cinq générations qui devraient se côtoyer dans les entreprises:
- Traditionalistes, nés avant 1946
- Baby Boomers, nés entre 1946 et 1964
- Gen X, nés entre 1965 et 1976
- Millennials (Gen Y), nés entre 1977 et 1997
- Gen 2020 (Gen C ou encore NetGen), nés après 1997
Un peu tiré par les cheveux pour la première et la dernière, vous dites? Regardez bien ce diagramme publié avec le HBR:

Les projections ici voient une décroissance constante des BabyBoomers. Rien de moins certain. Beaucoup d’entre eux reviennent au travail, leur revenu de retraite se révélant insuffisant alors que dans bien d’autres cas, c’est la caisse de retraite de l’entreprise qui est épuisée ou réutilisée à d’autres fins.
Bien des gouvernements sont en train de revoir leur politique de gestion des fonds publics de retraite et songent à mettre en place, comme en France, des incitatifs pour les entreprises à récupérer les savoirs de leurs retraités, comme je mentionnais dans ce billet.
D’ailleurs, le HBR note:
«In 1986, when the youngest Baby Boomers entered the workforce, the percentage of knowledge necessary to retain in your mind to perform well on the job was about 75 percent (according to research by Robert Kelley). For the other 25 percent, you accessed documentation, usually by looking something up in a manual. In 2009, only about 10 percent of knowledge necessary to perform well on the job is retained — meaning a myriad of other sources must be relied upon.»
Pour 90% des savoirs et des expertises nécessaires pour bien accomplir son travail, il faut avoir recours à d’autre chose que sa propre mémoire. De là l’importance de créer la mémoire d’entreprise™ et les retraités ont un rôle important à jouer dans cette construction.
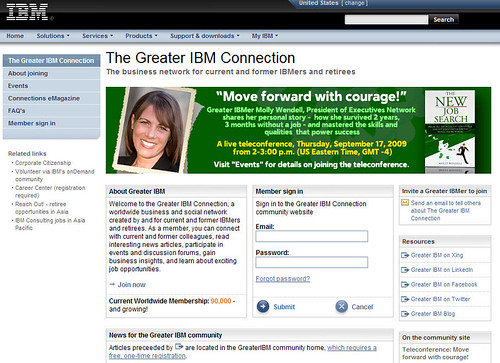
Plusieurs entreprises comme IBM (ci-dessus) et sites publics comme YourEncore proposent déjà aux retraités de troquer leurs expertise contre des $$$ sonnants et trébuchants et favorisent aussi le transfert d’expertise entre les jeunes travailleurs et leurs aînés à la retraite. Ce phénomène de création de communautés «idéagoriennes», soyez-en certains, va s’accélérer à partir de 2010!
Entreprise 2.0 LifeLogs Mémoire d'entreprise Web 3.0 Web sémantique
Le Web en temps réel: nouvel Eldorado ou étape transitoire?
10 août 2009Plus d’une semaine sans avoir écrit une seule ligne sur mon blogue… Syndrome de la page blanche??? Non, c’est juste une panne d’inspiration… Ce matin, c’est l’ami Christian Joyal, qui m’a «dépanné» sur Twitter. Christian venait de publier ce Tweet: @iamkiai: Betting on the Real-Time Web http://tinyurl.com/kk9a2g

Référence est faite à un article paru dans l’édition Web de BusinessWeek sur un nouveau phénomène qui est en train de monter en puissance, qui est la nouvelle «lubie» de l’ami Laurent Maisonnave et qui se nomme le «Real-Time Web». Laurent en parle comme du nouvel Eldorado du Web alors que John Borthwick, un des investisseurs de Twitter et CEO de betaworks en parle comme du «Next Big Thing». Pas d’accord. Je suis toujours d’avis que le Web 3.0 sera sémantique. Donc, le Real-Time Web est, à mon avis, une étape transitoire, ce que Tim O’Reilly et Dion Hinchcliffe ont identifié comme étant le Web Squared ou Web² . Mais cette étape, à n’en pas douter, est très importante.
Pour les investisseurs Internet tels que Borthwick ou Ron Conway, c’est un marché de plusieurs milliards de dollars au cours des cinq prochaines années. D’ailleurs l’article de BW propose un « slide show » de 59 diapos présentant toutes les compagnies ou « startups » présentant des produits à même de générer le Web en temps réel. Bien sûr, Twitter, TweetDeck, SeesmicDesktop ou FriedFeed, mais aussi Kyte et UStream ou ChartBeat, etc. Pas surprenant que Twitter ait levé récemment un 35 millions $.
It’s all about Data…
Vous connaissez ma lubie pour les données sur le Web…C’est là l’enjeu crucial… Le futur du Web va se jouer sur ces données. Les nôtres et celles des entreprises. Le Web 3.0 ou 4.0 ou sémantique ou autre sera celui qui réussira à faire un tout cohérent de ce que le Web 2.0 et le Web en temps réel ou Web² vont produire dans les prochaines années, soit une masse gigantesque de données. Sir Tim Berners-Lee parle du défi de lier toutes ces données et met de l’avant le W3C SWEO Linking Open Data community project.
De son côté, Google, qui d’autre, a lancé plus tôt cette année, sa nouvelle option Google Squared. Tiens donc… Et c’est la VP Marissa Mayer qui en avait fait l’annonce dans cette vidéo:
Cette même Marissa Mayer que j’avais rencontrée à Paris à la conférence LeWeb08. J’avais ensuite écrit dans mes billets post-conférence :
« Mais voilà qu’en début d’année, madame Mayer en remet une couche et signant sur le blogue de Google un long billet sur le futur de la recherche Web : «The Future of Search», un remarquable travail d’analyse de l’avenir de Google Search. Ce que je retiens, c’est le dernier paragraphe de la conclusion où elle parle de l’engin de recherche idéal et le reproduis ici :
Un engin intuitif et qui peut chercher de lui-même dans des carnets de vie personnels (ou LifeLogs) ou dans des banques de mémoire d’entreprise. Après Microsoft et Twine, Google entrera de plein pied dans le Web sémantique.»
Cet engin intuitif, c’est justement ce que Mme Mayer a présenté avec Google Squared, du moins à son premier stade de développement. Et comme je le disais, il y a d’autres joueurs, ne comptez pas Microsoft pour battu et regardez aussi des illustres inconnus pour le moment comme Twine et Darwin. Et en particulier cette dernière soit Darwin Development Corporation, une startup de Boston avec des ramifications montréalaises, fondée par Thierry Hubert. Les deux premiers paragraphes de leur présentation sur leur site en dit beaucoup :
« We believe that our Emergence Ranking™ of Web events produces a more meaningful result to users over the existing popularity ranking techniques. Our Awareness Engine™ is named DARWIN because it classifies and correlates Web events according to attractors of the chaotic nature of the Web 2.0.
DARWIN embraces the growing and unstructured Web events into a scaleable ecosystem transforming this “chaos” of information into a meaningful and targeted expression for its users and clients.»
Et le Web 3.0 basé en partie sur ces outils de recherche et d’analyse intuitive des données viendra finalement concrétiser en entreprise la dixième et dernière étape de ce que je nomme la Mémoire d’entreprise™. C’est Jon Husband qui m’avait mis sur cette piste il y a quelque temps en disant qu’il est buien beau de vouloir créer une mémoire en entreprise, de bâtir, communiquer, partager, identifier, agréger, récupérer, transmettre, documenter et gérer les savoirs mais il faut, pour faire tout cela, être capable de rechercher et trouver ces savoirs dans des montagnes de données ainsi générées en entreprise.
Pour cela, il faut certes lier les données, mais aussi un cortex virtuel pour faire les corrélations et extraire l’information du chaos de données…
Cloud Computing Identité numérique Sécurité des données Web 3.0 Web sémantique
Web 3.0. O’Reilly réplique avec le Web Squared…
25 juillet 2009C’est Tim Berners-Lee qui a mis le feu aux poudres… Depuis le temps que je vous écris que le Web en 2009-2010 fleurira de vos données «It’s all about Data» et que j’écris sur la guerre des données (Data War) qui se joue entre les grands comme Google, Microsoft, Amazon et autres, une guerre qui a pour armes d’accumulation massive le Cloud Computing, le scraping et la portabilité, je croyais donc le sujet entendu. Eh bien, non… Sir Thimoty, qui se présente toujours comme l’inventeur du World Wide Web (www ou encore W3) est venu en rajouter une couche avec une sortie publique fort remarquée, à la conférence TED, en février dernier.
Il est venu parler du futur Web, donc du Web 3.0 où tout n’est que données liées (Linked Data). Il est surtout venu faire la promotion du W3C SWEO Linking Open Data community project. La simple existence de ce projet et ses possibilités a excité les neurones de plusieurs et valu un super billet de vulgarisation dans ReadWriteWeb, édition française. Mais aussi une réplique de Tim O’Reilly et John Batelle, quelques mois plus tard, dans un webcast préparatoire à la conférence Web 2.0 Summit qui aura lieu en octobre à San Francisco. En effet, on ne détrône pas si facilement O’Reilly de sa paternité chiffresque…

Le SlideShare du webcast de Tim O’Reilly le 25 juin dernier
Il est donc revenu à la charge lors de ce webcast en proposant, comme le mentionne l’ami Fred Cavazza dans un excellent billet d’analyse, un Web intermédiaire, soit de Web Squared ou si vous préférez le Web². Comme l’écrit Fred: «Les explications autour de ce Web² sont résumées dans l’article fondateur suivant : Web Squared: Web 2.0 Five Years On ». C’est un article sur le site de Web 2.0 Summit qui appuie leurs prétentions mais les deux compères ont aussi pris le soin de rédiger un «White Paper» pour officialiser leur paternité sur le thème et l’idée.
Ce qui n’a pas empêché une autre grosse pointure, soit Dion Hinchcliffe de venir rajouter son propre grain de sel avec le billet: The Evolving Web In 2009: Web Squared Emerges To Refine Web 2.0. Hinchcliffe, qui écrit aussi pour ZDNet, donne des ateliers sur l’entreprise 2.0 à la conférence bostonienne Enterprise 2.0 et est, pour le bonheur de ceux et celles qui assistent à ses «workshops», un fervent adepte des schémas. Il a donc pondu le schéma suivant:
Hinchcliffe présente donc le Web² comme une suite logique et naturelle du Web 2.0, une forme d’évolution ou comme le dit Fred de «maturation qui va nous amener vers la prochaine itération majeure», soit le Web 3.0, le Web sémantique où les données et les liens fusionnent, là où se crée finalement une interrelation entre toutes les données afin de finalement donner un sens au Data Cloud, un sens généré au départ par les usagers eux-mêmes comme dans le projet original de Linked Data de Berners-lee.
Sa croissance est exponentielle. Ce nuage va devenir immense et pas seulement avec les données personnelles et tout ce que cela implique au niveau de leur entreposage et de leur portabilité mais aussi de leur protection et sécurité mais aussi celles des entreprises, à l’externe aussi bien qu’à l’interne… Un immense Cloud planétaire! Certains se réfèrent déjà au concept de Neural Net développé en science fiction et en référence aux travaux sur les Artificial Neural Networks, associés à l’intelligence artificielle. D’autres, comme Thierry Hubert, avec son projet Darwin, parlent de Virtual Cortex, issu directement de la «Théorie du Chaos»…
Bref un SupraNet où des agents intelligents se chargent de faire les corrélations pour récupérer de cet immense et chaotique nuage de données et de liens, les informations pertinentes, requises par les utilisateurs.
Et dire que Gene Roddenberry, il y a bien des années, a décidé de donner un nom très particulier au premier robot à cerveau positronique doté d’intelligence artificielle à apparaître dans sa série Star Trek. Ce nom, vous l’avez deviné, c’est : Data…