Google+ sera-t-il le dernier grand site de réseautage social du Web 2.0 ? Tout en moi voudrait qu’il n’en soit pas ainsi mais en même temps tout en moi crie le contraire… Oh… ce n’est pas le dernier site, la dernière communauté à apparaître mais je crois que tous ceux qui viendront APRÈS ne seront que copies ou tentatives de trouver une autre façon d’entrer en relation, de réinventer une formule déjà arrivée à maturité avec Facebook, LinkedIn et G+…
Alors, suis-je en train d’écrire sur le chant du cygne des réseaux sociaux ? Pas encore… Mais je crois que Google + est un avertissement en coup de tonnerre ! Le Web 2.0 a vécu ses plus belles années (2004-2010) et dans un cycle de vie normal, les adultes vieillissent et finissent par disparaitre et laisser la place à la jeunesse 3.0 ou 4.0 ou n’importe quelle autre appellation qui serai détermnée par les prochains gourous du Web ou de l’Internet à la Tim O’Reilly. À ce titre, laissez-moi vous entretenir des derniers travaux d’un de nos maîtres à penser québécois (pas un gourou) et selon moi, un homme qui a, ici comme en Europe, l’impact d’un Marshall McLuhan. J’ai nommé Michel Cartier.
Pas surprenant qu’à webcom, nous ayions donné son nom aux Prix Cartier remis aux personnes qui ont profondément marqué le milieu québécois des nouvelles technologies de l’information et de la communication. Dans une récente rencontre, Michel m’a fait part des résultats de ses dernières recherches sur les changements à apprivoiser au cours des 10 prochaines années avec comme danger de vivre de la pensée magique, c’est-à-dire de la technoscience… En fait, ce qui détermine notre avenir est plus complexe et implique aussi bien le technologique que l’économique et aussi le sociétal..
Trois vagues (rappelez-vous Alvin Toffler) qui ont simultanément atteint leur point de rupture entre 2000 et 2010 et qui, comme un Tsunami, balaient l’ancien ordre social pour le remplacer par de nouveaux modèles basés sur trois axes majeurs:1- La technologie, poussée par la convergence en mode intégré, 2- Un nouveau modèle économique de proximité et surtout 3- Un nouveau rapport au pouvoir basé sur la prise de parole.
Trois axes et autant de schémas…
Ces trois axes, Michel en a fait des schémas car il faut connaître l’homme pour comprendre que tout passe par les schémas. Donc, lors de notre rencontre, il m’a montré le fruit de ses dernières réflexions maintenant schématisées. C’est donc avec son accord, que je les diffuse ci-dessous. Comme vous le verrez, ils sont encore sous une forme brute, dessinés au crayon mais aussi sous forme évolutive car encore incomplets mais chacun venant expliquer ce qui se passe dans notre société et ce qui l’influencera dans les prochaines années. Et comme j’ai débuté ce billet par les réseaux sociaux, je reproduis donc le schéma sur l’axe sociétal.
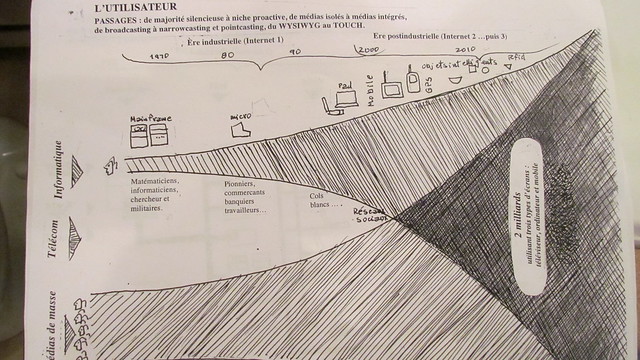
On y voit nettement la convergence des usages sociaux entre les médias de masse et l’informatique avec les divers outils inventés au fil de la ligne du temps tracée en haut. La question est de savoir qui cannibalise qui en bout de ligne pour capter l’audience de milliards d’internautes (2 milliards à date…) et de consommateurs de contenus sur trois types d’écrans, soit téléviseurs, ordinateurs et écrans mobiles. Pas inclue dans son schéma est la question des contenus ainsi générés et consommés.
Contenus et données auront besoin d’être entreposés, ce que l’on verra dans le schéma sur le système, et surtout organisés et présentés de façon cohérente, ce que l’on nomme actuellement la curation de contenus. Bref, la schéma de Michel me rappelle drôlement un autre schéma que j’utilise assez rarement dans mes conférences pour parler de la naissance du Web social, où les technologies sont vues comme un accélérateur de changement social et les forces sociales comme un transformateur du développement technologique. Cette interdépendance et interinfluence arrive juste à la jonction du schéma de Michel Cartier en 2004, l’année où justement le social et le technologique ont fusionné pour créer le Web social.:

Parler de technologies m’amène à présenter le schéma sur l’évolution de ces dernières et justement de prendre en compte la gestion de la conversation sociale et l’entreposage des données ainsi générées. J’ai souvent parlé les entrepôts de données et de la guerre que se livrent les grands comme Google et Amazon pour leur contrôle. Justement, cela touche d’une part la technologie mais aussi l’économie, soit les deux prochains schémas de Michel. Celui ci-dessous montre l’évolution des technologies informatiques depuis les années 70 en termes de traitement, de stockage et de réseaux.
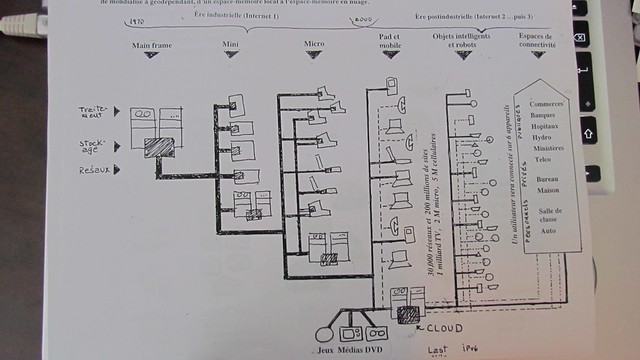
Bien évidemment, nous sommes passés du «mainframe» au client-serveur avec les minis puis les micros mais vous remarquerez que l’arrivée sur le marché des appareils mobiles change la donne. Encore une fois, on assiste à un changement de paradigme entre les années 2000 à 2010. Chris Andreson du magazine Wired a parlé de la mort du Web et de la prédominance de l’Internet avec maintenant 70% des contenus consommés par des applications accédant directement à Internet et non plus au Web via un navigateur. Mais la multiplication de ces appareils et applications a aussi multiplié la quantité de données disponibles et surtout à entreposer d’où le petit dessin en bas pour le Cloud Computimg ou en français «infonuagique» et son alter ego : les entrepôts de données.
Le guerre pour nos données et l’ordinateur planétaire…
Ce que le schéma ne montre pas cependant et que j’ai fait remarquer à Michel c’est que tous nos bidules mobiles, téléphones intelligents, iPads, iPods, lecteurs de livres numériques et netbooks n’ont pas de disques durs pour le stockage des données, d’où l’infonuagique et les entrepôts, d’où le RETOUR au mainframe ! Un seul ordinateur planétaire avec des milliards de terminaux qui sont actuellement des objets qui deviendront intelligents mais si on se projette juste un peu plus loin, des terminaux qui seront implantés chez les utilisateurs, directement… Bienvenue Cyborgs !
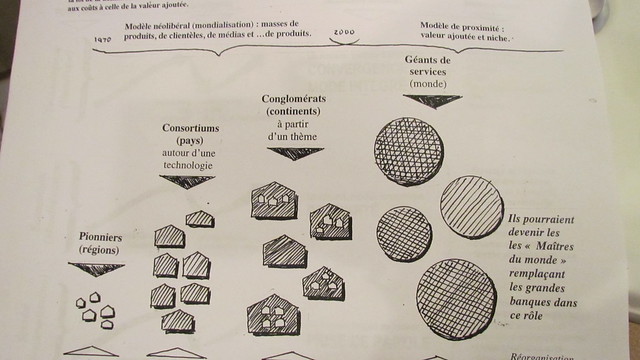
Et cette perspective fait saliver les grands de l’écomonie numérique… De là, le dernier schéma de Michel où l’économie a évolué des pionniers aux consortiums, des consortiums aux conglomérats et de ces derniers aux géants de service qui comme le mentionne Michel pourraient devenir les «maîtres du monde» remplaçant au passage les grandes banques qui jouent actuellement ce rôle. Et qui sont ces géants ? Si vous avez répondu Google, Microsoft, Facebook, Amazon, Salesforce, vous avez vu juste. Et c’est justement ces grands de l’économie numérique qui actuellement se livrent la «data war» pour le contrôle non seulement de vos données mais aussi de l’ordinateur central et planétaire.
Oh, en passant, j’ai oublié de mentionner, concernant le schéma sur la technologie, que Michel distingue Internet 1 et Internet 2 car en effet, il y a actuellement deux Internets. Celui sur lequel nous évoluons actuellement et qui a permis le W3. Au départ, on le nommait ARPANET et il était réservé aux militaires et aux chercheurs universitaires.
Comme Internet 1 est devenu hyper commercial et social et surtout encombré, devinez où ont migré les militaires et chercheurs ? Sur Internet 2 et ce nouvel Internet possède des caractéristiques de connectivité impressionnantes, comme le démontre la capture d’écran d’une de mes «slides». Imaginez… Le CERN a établi en 2005 le record encore inégalé : 5,44 Gigabits/seconde… Et dire que l’infrastructure de transport du PC1 Cable peut permettre à Internet 2 d’atteindre 640 Gigabits/seconde…. Bienvenue à Internet 2 et à quand Internet 3, 4 ou 5?

En fait, il n’y a pas de limites au nombre d’Internets ou comme les appelle Michel, espaces de connectivité… Bref où est le Web 2.0 dans tout cela ? Catalyseur de changement entre 2005 et 2010, il risque de passer bientôt à l’Histoire. O’Reilly parle de Web Squared, Berners-Lee de Web sémantique, Anderson d’Internet des choses. Et Michel Cartier lui, parle d’une immense fracture mondiale, de bouleversements que nous vivons à tous les jours. Pas seulement dans notre utilisation des technologies mais aussi dans notre vie sociale, économique, politique et même environnementale !
Bienvenue dans un monde post Web 2.0 mais pas pour les entreprises, surtout à l’interne car ces dernières sont presque deux à trois ans en retard sur les usages personnels sur le Web et sur Internet. Et loin de s’amenuiser, cet écart grandit !!!
MAJ1
J’ai eu beaucoup de commentaires et de retweets à la suite de ce billet mais malheureusement, les commentaires ne se sont pas inscrits ci-dessous, dans l’espace prévu à cette fin. Donc, je reproduis ici le courriel que j’ai reçu d’André Mondoux :
Bonjour Claude.
Tel que promis, deux articles. Ils seront publiés – si ce n’est déjà fait – dans les semaines qui suivent. Je n’ai pas les références exactes (ce sont deux revues françaises : Les cahiers du numérique et TERMINAL), mais si tu en as besoin, je te les ferai parvenir. L’idée de fond est que ce n’est pas tant le retour du mainframe dans la mesure où avec ce dernier les rapports de force/politiques étaient clairs : le centre et le « dumb terminal »… Maintenant, la structure ressemble effectivement au mainframe, mais ce dernier apparait non plus comme un rapport politique, mais bien l’horizon du monde lui-même (le dumb est devenu « client » supposément émancipé/ la technique semble « autonome » – ce que Cartier nomme technoscience….). Les conséquences et implications sont décrites dans les articles que je te fais parvenir bien humblement.
Cordialement,
André
J’aime bien cette précision sur le mainframe: du rapport de forces politico-technologique entre un centre intelligent et une périphérie bête et stupide alors que le SYSTÈME aurait évolué pour devenir autonome et inclusif, l’ordinateur planétaire ou le système-monde comme le nomme André Mondoux, étant connecté à l’intelligence et aux émotions consommatrices de deux milliards d’humains/clients. Et oui, je vois déjà d’autres commentaires affluer aux sujet de la Matrice et de Big Brother… Ce faisant, je joins le Pdf du texte d’André intitulé Mon Big Brother à moi.
MAJ2:
Et comme une mise à jour ne vient jamais seule et surtout comme le hasard fait bien les choses, Chris Anderson et son magazine Wired viennent remettre de l’eau à mon moulin en cette fin de journée. Sur Twitter, j’ai donc intercepté un lien qui m’a amené sur un article tout frais paru (45 mins.) et qui porte sur quoi ? Je vous le donne en mille: « The Coming Cloud Wars: Google+ vs Microsoft (plus Facebook)». Bonne lecture !