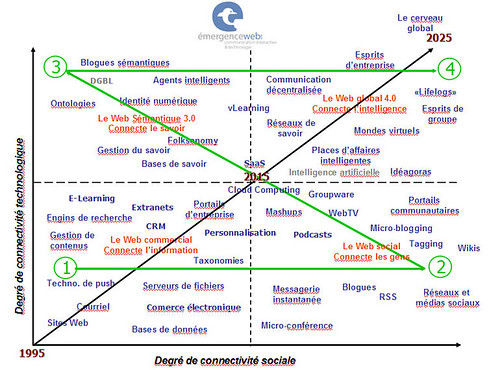
J’ai eu la semaine dernière, une conversation passionnante avec René Barsalo, directeur, Stratégie et partenariats de la SAT, Société des Arts technologiques. La conversation a porté sur notre civilisation de plus en plus numérique ou «digitale», sur les données que nous générons quotidiennement et sur l’identité numérique que nous nous bâtissons. Une identité faite de documents Word, PowerPoint, Excel mais aussi d’informations personnelles incluses dans nos profils sur Facebook, LinkedIn et autre sites de «networking social», de photos, de vidéos et de micro-conversations à la SMS, Twitter, Skype ou encore Seesmic. Le tout j’expliquais à René, doit former nos «LifeLogs» ou carnets de vie, la génération évoluée et 4.0 des blogues…
Le projet de LifeLog, MyLifeBits
Pour sa part, René travaille beaucoup à la SAT sur l’arrivée prochaine de la vague audiovisuelle (téléprésence, télémanipulation, espaces branchés, etc.), qui nous fera passer de plus en plus en mode « temps réel » plutôt qu’en mode asynchrone. Il se penche aussi sur les impacts à surveiller : sur nos partenariats, nos carrières, nos traces, notre société. Bref, il pousse notre conception actuelle du Web (2.0) vers une nouvelle, déjà identifiée comme celle du Web 3D mais pose aussi une autre question essentielle, soit celle de la place que nous occupons dans la société réelle et celle que nous occuperons dans la société numérique et de plus en plus virtuelle que se met rapidement en place.
Une place individuelle qu’on nomme «identité numérique» (pensez au ePortfolio de Serge Ravet) mais aussi collective et que nous nommerons comment : Culturello-numérique ? La bataille sur la diversité culturelle revue et corrigée et ayant une portée beaucoup plus vaste car touchant pas seulement le production culturelle traditionnelle mais TOUTE la production culturelle, professionnelle, sociale et personnelle de tous les membres de la société. Et quel poids aura le Québec face à des géants comme les USA, l’Europe et la Chine ? René prétend, avec raison, que le Québec occupe une position stratégique, un créneau que nous pourrions occuper si nous ne dormions pas collectivement au gaz comme c’est la cas présentement.
Géographiquement le Québec occupe, d’une part, une place stratégique pour la transmission de données par fibre optique, Il est sur le chemin le plus court pour relier l’Europe et la Chine, donc en mesure de profiter des retombées potentielles de l’installation d’une autoroute à méga-débit, un peu comme le PC1-Cable (PC pour Pacific Crossing et à 640 Gigabits/seconde) qui relie actuellement le réseau WIDE Internet (Widely Integrated Distributed Environment) au Japon au réseau américain Abilene (Advanced Networking for Learning-edge Research and Education) du projet nommé ambitieusement Internet2.
Le Québec pourrait profiter de ce nouvel Internet qui se met en place aux USA et au Japon, certes mais aussi en Europe avec le Projet DANTE (Delivery of Advanced Network Technology to Europe) et son réseau GÉANT2 mais aussi en Chine avec CERNET2 (China Education and Research Network). À la croisée des chemins numériques et virtuels, le Québec pourrait se tailler une place de choix, tant au point de vue économique, technologique que politique et socio-culturel.

L’urgence pour nos gouvernements locaux est d’investir au plus vite dans les infrastructures du futur et non seulement dans celles du présent. Imaginez seulement ce que le réseau GÉANT2 a pu réaliser pour le CERN (Organisation européenne pour la recherche nucléaire) et le projet EGEE (Réalisation de grilles pour la science en ligne) :
«Au cours du mois d’avril 2006, la Grille a en effet été utilisée dans la lutte contre le virus mortel H5N1 de la grippe aviaire. Grâce à l’infrastructure de grille du projet EGEE, six laboratoires en Europe et en Asie ont analysé 300 000 composants de médicaments potentiels pour le traitement de la maladie. Cette recherche, menée sur 2 000 ordinateurs dans le monde entier avec l’aide d’un logiciel développé au CERN, a permis d’identifier et de classer les composés chimiques les mieux à même d’inhiber l’enzyme N1 du virus. En un mois, la collaboration est parvenue à traiter autant de données qu’un seul ordinateur en 100 ans».
C’est donc l’utilisation en réseau ultra-rapide du potentiel des ordinateurs de la planète, ce que l’on nomme le «Grid Computing» mais ces «grilles« seront bientôt remplacées par un nuage… Le «Cloud Computing», soit la possibilité de transférer dans le nuage Internet, l’ensemble des données et applications de la planète, le sujet de l’heure et dont j’ai traité en détails ICI.
Lors de mon récent passage à San Francisco, pour le conférence Web 2.0 Expo, j’avais relaté l’entrevue entre Tim O’Reilly et Jonathan Schwartz , président et CEO de Sun Microsystems, dont voici un extrait :
, président et CEO de Sun Microsystems, dont voici un extrait :
«Arrivé avec quelques minutes de retard, je comprends que la conversation va dans les deux sens, que le CEO a parlé avec beaucoup de ferveur de MySQL et que O’Reilly prend beaucoup de place. Il tente d’amener Schwartz sur ses terrains de prédilection soit le «Cloud Computing», et «The Internet as the OS», part dans de longues réflexions alors que Schwartz attend patiemment qu’il lui redonne la parole par une question…

La conversation prend une tournure très intéressante quand Schwartz finit par aborder innocemment le sujet des données et surtout les méga-entrepôts de données. Il lance une des meilleures citations de la conférence :« If the network is the computer, data is the currency»…Et fait surprenant, il ouvre la porte verte… En effet, selon lui, Sun Microsystems se doit d’être «power efficient» dans son offre de serveurs et que la nouvelle gamme ira en ce sens avec comme objectif de couper leur consommation d’électricité du cinquième.
Comme Sun est un des grands fournisseurs de serveurs, ses clients sont les propriétaires des entrepôts de données, les Google, Microsoft et maintenant Amazon et SalesForce. Selon le CEO, ces derniers ne devront pas seulement avoir des serveurs moins gourmands en électricité mais aussi avoir des entrepôts-containers… Et dans cette partie, Sun ne veut pas être uniquement un fournisseur d’infrastructure. Elle veut jouer à armes égales et aussi avoir ses propres entrepôts, lui donnant ainsi un avantage concurrentiel…
Ce qu’il veut dire par entrepôts-containers, c’est que Sun, Google et les autres doivent penser à des entrepôts mobiles, qui peuvent suivre les sources d’énergie. Encore plus intéressant, il en est arrivé à parler des entrepôts situés dans des endroits où on réchauffe les équipements au lieu de les climatiser. De l’antigel au lieu de l’air climatisé… Et aussi en arriver à les automatiser complètement. Un peu comme les postes et les centrales hydroélectriques qui sont opérés à distance… En ce sens, certains joueurs comme Microsoft planifient l’installation d’entrepôts en Sibérie…
Vous voyez les opportunités ici, entre autres, pour l’économie québécoise. En effet, le Québec est un pays nordique et théoriquement assez froid. Il a une source inépuisable d’énergie : l’eau. Et il a des infrastructures industrielles à recycler dont des alumineries, idéales pour installer des méga-entrepôts de données puisque déjà équipées de l’infrastructure de transformation électrique. Vous imaginez pour l’économie de Shawinnigan ? Ou de Jonquière, ou de Baie-Comeau ? Le gouvernement et l’entreprise privée devraient comprendre et exploiter ce nouvel atout…

Cela me fait penser à ce qu’écrit Nicholas Carr dans son bouquin «The Big Switch», sur le fait que les compagnies comme Google sont en train de devenir des nouvelles «Utilities». Les précédentes fournissent de l’énergie. Les prochaines fourniront un nouveau service essentiel : l’Internet et nos données. Schwartz et Sun ont bien compris… «Free software and free ideas are the best way to reach the consumers». Une fois atteints et fidélisés, Sun peut se concentrer à faire son $$$ ailleurs soit en devenant un des joueurs majeurs de la «Data War» et aussi en vendant ses serveurs à Google, Amazon, et autres nouvelles «Utilities».
Ce que je ne savais pas alors, c’est que le gouvernement du Québec a justement refusé la permission à Google de venir s’installer au Québec… Il y a des sous-ministres qui pensent plus à ne pas faire de vagues jusqu’à leur retraite plutôt qu’à prendre des risques pour assurer le développement économique et technologique du Québec et ainsi assurer notre compétitivité sur la scène mondiale où se joue actuellement le grand positionnement technologique, la «Data War» dont je parlais…
Et pourtant, le Québec pourrait encore une fois tabler sur ses atouts traditionnels : sa situation géographique et son climat, ses ressources naturelles, plus particulièrement l’eau et l’hydroélectricité mais aussi la créativité de l’ensemble de sa population qui l’a longtemps placé au-devant de l’industrie du numérique, tant dans les entreprises du Web 1.0 avant l’éclatement de la Bulle, que maintenant avec l’industrie du jeu, celle du eCommerce et du Web 2.0 mais aussi du Web 3D avec des initiatives comme le Panoscope 360 de la SAT et de l’UdM, l’unité Métalab ou encore le programme TOT.

Car il faut comprendre, comme se tue à l’expliquer René Barsalo, que le futur du Québec n’est pas dans les technologies du Web 2.0 mais bien dans celles du Web 3.0 ou 3D et de ce que nous ferons des opportunités que nous offrent nouvel Internet et ses réseaux. Avoir sur son territoire, à la fois les meilleurs réseaux et les entrepôts qui feront partie du «Nuage Internet» est essentiel à notre développement en tant que société et il est urgent d’agir !!!